分析
bangdream查卡器:https://bestdori.com/
其中所有卡面(日服)都在 https://bestdori.com/tool/explorer/asset/jp/characters/resourceset 路径下
可以看到大量的命名为res + num1 + num2的文件夹
其中num1为角色的编号,num2为卡片的编号,res001001代表第一个角色的第一张卡牌
点进去可以看到
card_normal.png -觉醒前卡面
card_after_training.png -觉醒后卡面
trim_normal.png -觉醒前卡面(无背景)
trim_after_training.png -觉醒后卡面(无背景)
随便一个为例,右键在新页面打开卡牌,看到URL为 https://bestdori.com/assets/jp/characters/resourceset/res001024_rip/card_after_training.png
那么res001024就是所有卡牌URL中唯一的变量,只要能获取到所有的res + num1 + num2就能轻松实现了
如果从前端获取,虽然可是实现,但是太麻烦了
在 https://bestdori.com/tool/explorer/asset/jp/characters/resourceset 打开F12控制台,寻找后端请求
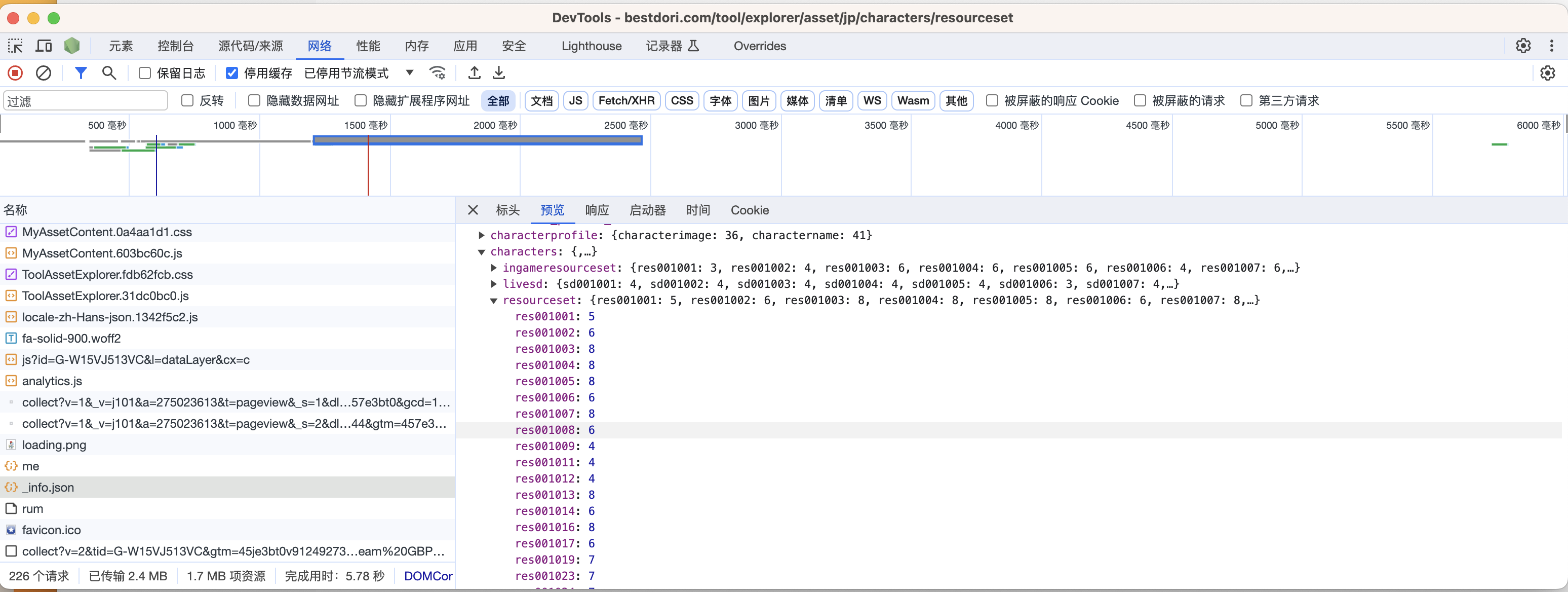
这样就能直接get到所有的res列表了
实现代码
import json
import os
import requests as re
# 每次爬取本地保留一份txt,对比检测更新
def save_card_list(data):
with open("card_list.json", "w") as f:
json.dump(data, f)
def load_card_list():
try:
with open("card_list.json", "r") as f:
return json.load(f)
except FileNotFoundError:
return []
role_dict = {
'res001': '户山 香澄',
'res002': '花园 多惠',
'res003': '牛込 里美',
'res004': '山吹 沙绫',
'res005': '市谷 有咲',
'res006': '美竹 兰',
'res007': '青叶 摩卡',
'res008': '上原 绯玛丽',
'res009': '宇田川 巴',
'res010': '羽泽 鸫',
'res011': '弦卷 心',
'res012': '濑田 薰',
'res013': '北泽 育美',
'res014': '松原 花音',
'res015': '奥泽 美咲',
'res016': '丸山 彩',
'res017': '冰川 日菜',
'res018': '白鹭 千圣',
'res019': '大和 麻弥',
'res020': '若宫 伊芙',
'res021': '凑 友希那',
'res022': '冰川 纱夜',
'res023': '今井 莉莎',
'res024': '宇田川 亚子',
'res025': '白金 燐子',
'res026': '仓田 真白',
'res027': '桐谷 透子',
'res028': '广町 七深',
'res029': '二叶 筑紫',
'res030': '八潮 瑠唯',
'res031': 'LAYER',
'res032': 'LOCK',
'res033': 'MASKING',
'res034': 'PAREO',
'res035': 'CHU²',
'res036': '高松 燈',
'res037': '千早 愛音',
'res038': '要 楽奈',
'res039': '長崎 そよ',
'res040': '椎名 立希'
}
def init_folder():
for role in role_dict:
folder_name = role_dict.get(role)
os.makedirs('card/' + folder_name, exist_ok=True)
init_folder()
CARD_NORMAL = '_rip/card_normal.png'
CARD_TRAIN = '_rip/card_after_training.png'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Referer': 'https://bestdori.com/',
'Host': 'bestdori.com'
}
card_url = 'https://bestdori.com/assets/jp/characters/resourceset/'
json_url = 'https://bestdori.com/api/explorer/jp/assets/_info.json'
error_list = []
data = json.loads(re.get(json_url).text).get('characters').get('resourceset')
local_card_list = load_card_list()
card_list = [key for key in data.keys() if key.startswith('res')]
new_card_list = [key for key in card_list if key not in local_card_list]
if len(new_card_list) > 0:
print("卡片有更新")
save_card_list(card_list)
card_list = new_card_list
else:
print("没有新卡片")
print(card_list)
# 断点续传,第一次下载改为res001001即可
start_index = card_list.index('res016001')
card_list = card_list[start_index:]
for res in card_list:
print("当前卡片编号为:", res)
try:
print("开始下载普通卡面")
card_normal = re.get(card_url + res + CARD_NORMAL)
except:
print("下载失败")
error_list.append(res)
pass
if (len(card_normal.content) > 100000):
character = res[:6]
with open('card/' + role_dict.get(character) + '/' + res[-3:] + 'normal.png', 'wb') as f:
f.write(card_normal.content)
f.close()
try:
print("开始下载特训卡面")
card_train = re.get(card_url + res + CARD_TRAIN)
except:
print("下载失败")
error_list.append(res)
pass
if (len(card_train.content) > 100000):
character = res[:6]
with open('card/' + role_dict.get(character) + '/' + res[-3:] + 'training.png', 'wb') as f:
f.write(card_train.content)
f.close()
print("下载完毕")
print("下载失败列表如下")
print(error_list)参考文献:[1]. 铁铲胡桃,【BangDream】爬取日服现有卡面(含下载),https://www.bilibili.com/read/cv6711248
注意卡片编号不一定连续,例如在bestdori可以发现res022071和res022073都存在而res022072不存在,所以出现编号不连续不一定是因为下载失败,还有卡面觉醒前后立绘一致的情况
扩展
下载的卡面可以通过目前主流的模型进行放大,可以拿来当做壁纸,或者搭一个图床,随机图片api,如https://nanxiaoxiong.com/bangdreamapi.php
优化
- 多线程下载,下载任务只用卡牌编号区分,所以把卡牌编号list分片即可,提高效率
- 可视化工具方便使用

{kind=link}
文章有(3)条网友点评
感谢分享,很方便就把卡面全部下载好了,我也通过代码学习到了一些新东西。
PS:81行从丸山彩开始循环,res001-res015就无法下载了,index里改成res001001更好一点。
@ hina start_index改为:start_index = card_list.index(“res001001”)
除此之外我添加了一个retry_download函数。下载完成后,能重新下载失败的卡面(其实就是遍历下载error_list= =)
def retry_download(error_list):
for res in error_list:
print(“重新下载失败的文件:”, res)
try:
print(“开始下载普通卡面”)
card_normal = re.get(card_url + res + CARD_NORMAL)
except:
print(“下载失败”)
continue
if len(card_normal.content) > 100000:
character = res[:6]
with open(
“card/” + role_dict.get(character) + “/” + res[-3:] + “normal.png”, “wb”
) as f:
f.write(card_normal.content)
try:
print(“开始下载特训卡面”)
card_train = re.get(card_url + res + CARD_TRAIN)
except:
print(“下载失败”)
continue
if len(card_train.content) > 100000:
character = res[:6]
with open(
“card/” + role_dict.get(character) + “/” + res[-3:] + “training.png”,
“wb”,
) as f:
f.write(card_train.content)
然后判断语放在最下面就行了
if len(error_list) > 0:
retry = input(“是否重新下载失败的卡面?(y/n): “)
if retry == “y”:
retry_download(error_list)
else:
print(“结束下载”)
else:
print(“所有文件下载完成”)
yandanxvurulmus.nTZJjML6TsB8